The last modifications of this post were around 4 years ago, some information may be outdated!
Sometimes, we wanna couple multiple dataframes together. In this note, I use df as DataFrame, s as Series.
Libraries
import pandas as pd
import numpy as np
Coupling dfs with merge()
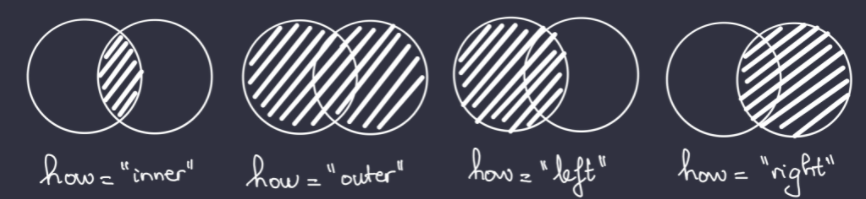
There are 4 types of merging, like in SQL.
- Inner: only includes elements that appear in both dataframes with a common key.
- Outer: includes all data from both dataframes.
- Left: includes all of the rows from the "left" dataframe along with any rows from the "right" dataframe with a common key; the result retains all columns from both of the original dataframes.
- Right: includes all of the rows from the "right" dataframe along with any rows from the "left" dataframe with a common key; the result retains all columns from both of the original dataframes.
On the same column name,
df_left = pd.merge(left=df1, right=df2, how='left', on='Col_1', suffixes=('_df1', '_df2'))
df_right = pd.merge(left=df1, right=df2, how='right', on='Col_1', suffixes=('_df1', '_df2'))
display_side_by_side(df1, df2, df_left, df_right)
| Col_1 | Col_2 |
|---|
| 0 | A | 1 |
|---|
| 1 | E | 3 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2 |
|---|
| Col_1 | Col_2 |
|---|
| 0 | A | 1 |
|---|
| 1 | B | 2 |
|---|
| 2 | C | -3 |
|---|
| 3 | F | -4 |
|---|
| 4 | E | NaN |
|---|
| Col_1 | Col_2_df1 | Col_2_df2 |
|---|
| 0 | A | 1 | 1 |
|---|
| 1 | E | 3 | NaN |
|---|
| 2 | C | NaN | -3 |
|---|
| 3 | D | NaN | NaN |
|---|
| 4 | B | 2 | 2 |
|---|
| Col_1 | Col_2_df1 | Col_2_df2 |
|---|
| 0 | A | 1 | 1 |
|---|
| 1 | E | 3 | NaN |
|---|
| 2 | C | NaN | -3 |
|---|
| 3 | B | 2 | 2 |
|---|
| 4 | F | NaN | -4 |
|---|
df_inner = pd.merge(left=df1, right=df2, on='Col_1', suffixes=('_df1', '_df2'))
df_outer = pd.merge(left=df1, right=df2, how='outer', on='Col_1', suffixes=('_df1', '_df2'))
display_side_by_side(df1, df2, df_inner, df_outer)
| Col_1 | Col_2 |
|---|
| 0 | A | 1 |
|---|
| 1 | E | 3 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2 |
|---|
| Col_1 | Col_2 |
|---|
| 0 | A | 1 |
|---|
| 1 | B | 2 |
|---|
| 2 | C | -3 |
|---|
| 3 | F | -4 |
|---|
| 4 | E | NaN |
|---|
| Col_1 | Col_2_df1 | Col_2_df2 |
|---|
| 0 | A | 1 | 1 |
|---|
| 1 | E | 3 | NaN |
|---|
| 2 | C | NaN | -3 |
|---|
| 3 | B | 2 | 2 |
|---|
| Col_1 | Col_2_df1 | Col_2_df2 |
|---|
| 0 | A | 1 | 1 |
|---|
| 1 | E | 3 | NaN |
|---|
| 2 | C | NaN | -3 |
|---|
| 3 | D | NaN | NaN |
|---|
| 4 | B | 2 | 2 |
|---|
| 5 | F | NaN | -4 |
|---|
On the different column names,
df_left = pd.merge(left=df1, right=df2, how='left', left_on='Col_1', right_on='Col_X', suffixes=('_df1', '_df2'))
display_side_by_side(df1, df2, df_left)
| Col_1 | Col_2 |
|---|
| 0 | A | 1 |
|---|
| 1 | E | 3 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2 |
|---|
| Col_X | Col_2 |
|---|
| 0 | A | 1 |
|---|
| 1 | B | 2 |
|---|
| 2 | C | -3 |
|---|
| 3 | F | -4 |
|---|
| 4 | E | NaN |
|---|
| Col_1 | Col_2_df1 | Col_X | Col_2_df2 |
|---|
| 0 | A | 1 | A | 1 |
|---|
| 1 | E | 3 | E | NaN |
|---|
| 2 | C | NaN | C | -3 |
|---|
| 3 | D | NaN | NaN | NaN |
|---|
| 4 | B | 2 | B | 2 |
|---|
The result keeps both Col_1 and Col_X while in the case of the same column name, there is only 1 column. Other words, in this case, we only want to keep Col_1 and don't need Col_X. How to do that?
df_left = df1.set_index('Col_1').join(df2.set_index('Col_X'), how="left", lsuffix="_df1", rsuffix="_df2").reset_index()
display_side_by_side(df1, df2, df_left)
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | E | 3.0 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2.0 |
|---|
| Col_X | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | B | 2.0 |
|---|
| 2 | C | -3.0 |
|---|
| 3 | F | -4.0 |
|---|
| 4 | E | NaN |
|---|
| Col_1 | Col_2_df1 | Col_2_df2 |
|---|
| 0 | A | 1.0 | 1.0 |
|---|
| 1 | E | 3.0 | NaN |
|---|
| 2 | C | NaN | -3.0 |
|---|
| 3 | D | NaN | NaN |
|---|
| 4 | B | 2.0 | 2.0 |
|---|
Concatenate dfs with concat()
df_concat_0 = pd.concat([df1, df2])
df_concat_1 = pd.concat([df1, df2], axis=1)
df_concat_0_idx = pd.concat([df1, df2], ignore_index=True)
display_side_by_side(df1, df2)
display_side_by_side(df_concat_0, df_concat_1, df_concat_0_idx)
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | E | 3.0 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2.0 |
|---|
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | B | 2.0 |
|---|
| 2 | C | -3.0 |
|---|
| 3 | F | -4.0 |
|---|
| 4 | E | NaN |
|---|
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | E | 3.0 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2.0 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | B | 2.0 |
|---|
| 2 | C | -3.0 |
|---|
| 3 | F | -4.0 |
|---|
| 4 | E | NaN |
|---|
| Col_1 | Col_2 | Col_1 | Col_2 |
|---|
| 0 | A | 1.0 | A | 1.0 |
|---|
| 1 | E | 3.0 | B | 2.0 |
|---|
| 2 | C | NaN | C | -3.0 |
|---|
| 3 | D | NaN | F | -4.0 |
|---|
| 4 | B | 2.0 | E | NaN |
|---|
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | E | 3.0 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2.0 |
|---|
| 5 | A | 1.0 |
|---|
| 6 | B | 2.0 |
|---|
| 7 | C | -3.0 |
|---|
| 8 | F | -4.0 |
|---|
| 9 | E | NaN |
|---|
Combine 2 dataframes with missing values
We consider a situation in that we need to combine 2 dfs containing missing values in each. The missing values will be filled by taking from the others. For example, the value of C in the left df can be fulfilled by the value of C in the right df.
df_comb = df1.copy()
df_new = df_comb.fillna(df2)
display_side_by_side(df1, df2, df_comb, df_new)
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | E | 3.0 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2.0 |
|---|
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | B | 2.0 |
|---|
| 2 | C | -3.0 |
|---|
| 3 | F | -4.0 |
|---|
| 4 | E | NaN |
|---|
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | E | 3.0 |
|---|
| 2 | C | NaN |
|---|
| 3 | D | NaN |
|---|
| 4 | B | 2.0 |
|---|
| Col_1 | Col_2 |
|---|
| 0 | A | 1.0 |
|---|
| 1 | E | 3.0 |
|---|
| 2 | C | -3.0 |
|---|
| 3 | D | -4.0 |
|---|
| 4 | B | 2.0 |
|---|

💬 Comments