The last modifications of this post were around 4 years ago, some information may be outdated!
This is a draft, the content is not complete and of poor quality!
What's the idea of Pipeline?
Stack multiple processes into a single (scikit-learn) estimation.
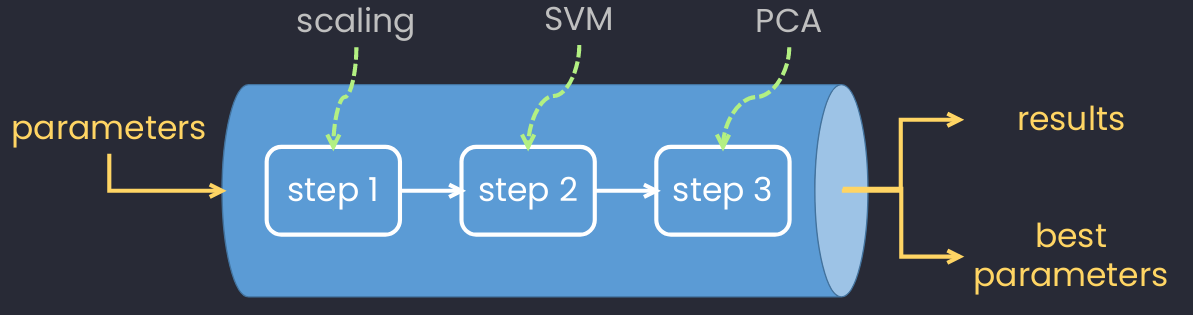
An example of using pipeline in Machine Learning with 3 different steps.
Why pipeline?
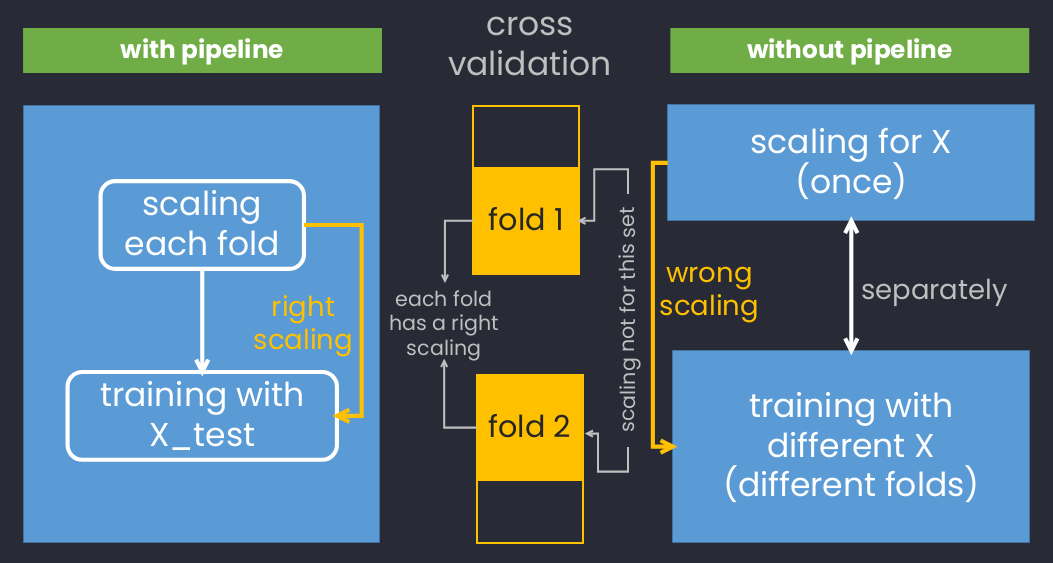
An example of using scaling with cross-validation with and without using pipeline.
Pipeline in Scikit-learn
Below sample codes come from this example.
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
pca = PCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='rbf', class_weight='balanced')
model = make_pipeline(pca, svc)Difference between Pipeline and make_pipeline:
Pipeline: you can name the steps.make_pipeline: no need to name the steps (use them directly).
make_pipeline(PCA(), SVC())Pipeline(steps=[
('principle_component_analysis', PCA()),
('support_vector_machine', SVC())
])Using with GridSearch
# Using with GridSearch (to choose the best parameters)
from sklearn.model_selection import GridSearchCV
param_grid = {'svc__C': [1, 5, 10, 50], # "svc": name before, "C": param in svc
'svc__gamma': [0.0001, 0.0005, 0.001, 0.005]}
grid = GridSearchCV(model, param_grid, cv=5, verbose=1, n_jobs=-1)
grid_result = grid.fit(X, y)
best_params = grid_result.best_params_
# predict with best params
grid.predict(X_test)In case you wanna use best_params,
best_params['svc__C']
best_params['svc__gamma']Take care the cross validation (take a long time to run!!!,
from sklearn.model_selection import cross_val_score
cv_scores = cross_val_score(grid, X, y)
print('Accuracy scores:', cv_scores)
print('Mean of score:', np.mean(cv_scores))
print('Variance of scores:', np.var(cv_scores))Example
- Face Recognition using SVM -- Open in HTML -- Open in Colab.
💬 Comments