
What?
The key idea is that for each point of a cluster, the neighborhood of a given radius has to contain at least a minimum number of points.
DBSCAN
- "DBSCAN" = Density-based-spatial clustering of application with noise.
- Separate clusters of high density from ones of low density.
- Can sort data into clusters of varying shapes.
- Input: set of points & neighborhood N & minpts (density)
- Output: clusters with density (+ noises)
- Each point is either:
- Core point: has at least minpts points in its neighborhood.
- Border point: not a core but has at least 1 core point in its neighborhoods.
- Noise point: not a core or border point.
- Phase:
- Choose a point → it's a core point?
- If yes → expand → check core / check border
- If no → form a cluster
- Repeat to form other clusters
- Eliminate noise points.
- Choose a point → it's a core point?
- Pros:
- Discover any number of clusters (different from K-Means which need an input of number of clusters).
- Cluster of varying sizes and shapes.
- Detect and ignore outliers.
- Cons:
- Sensitive → choice of neighborhood parameters (eg. If minpts is too small → wrong noises)
- Produce noise: unclear → how to calculate metric indexes when there is noise.
HDBSCAN
- High DBSCAN.
- Difference between DBSCAN and HDBSCAN:
- HDBSCAN: focus much on high density.
- DBSCAN: create right clusters but also create clusters with very low density of examples (Figure 1).
- Check more in this note.
- Reduce the speed of clustering in comparision with other methods (Figure 2).
- HDBScan has the parameter minimum cluster size (
min_cluster_size), which is how big a cluster needs to be in order to form.
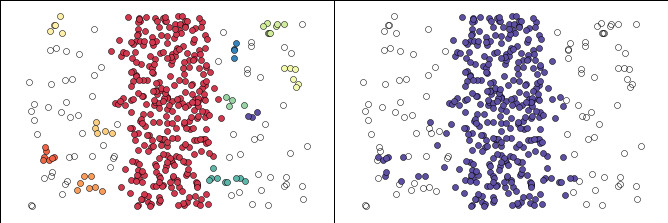
Figure 1. Difference between DBSCAN (left) and HDBSCAN (right). Source of figure.
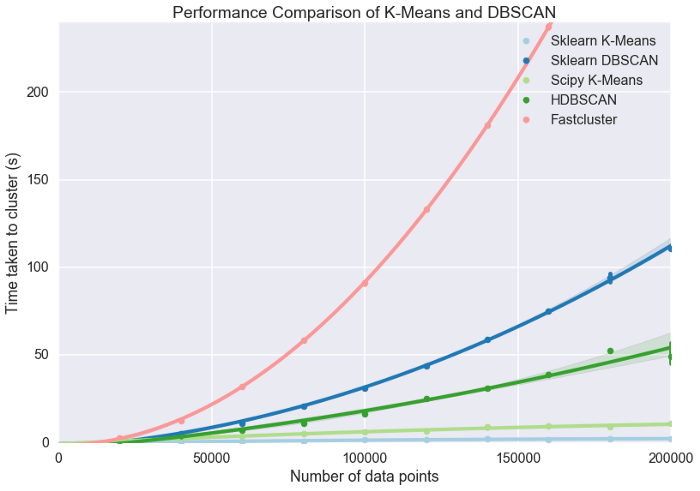
Figure 2.Performance comparison of difference clustering methods. HDBSCAN is much faster than DBSCAN with more data points. Source of figure.
When?
- We are not sure the number of clusters (like in KMeans)
- There are outliers or noises in data.
- Arbitrary cluster's shape.
In Code
DBSCAN with Scikit-learn
from sklearn.cluster import DBSCAN
clr = DBSCAN(eps=3, min_samples=2)clr.fit(X)
clr.predict(X)# or
clr.fit_predict(X)Parameters (others):
min_samples: min number of samples to be called "dense"eps: max distance between 2 samples to be in the same cluster. Its unit/value based on the unit of data.- Higher
min_samples+ lowerepsindicates higher density necessary to form a cluster.
Attributes:
clr.labels_: clusters' labels.
HDBSCAN
For a ref of paramaters, check the API.
from hdbscan import HDBSCAN
clr = HDBSCAN(eps=3, min_cluster_size=3, metric='euclidean')Parameters:
min_cluster_size: [ref] the smallest size grouping that you wish to consider a cluster.min_samples: [ref] The number of samples in a neighbourhood for a point to be considered a core point. The larger value the more points will be declared as noise & clusters will be restricted to progressively more dense areas.Working with DTW (Dynamic Time Warping) (more):
metric='precomputed'[ref]from dtaidistance import dtw
matrix = dtw.distance_matrix_fast(series) # something likes that
model = HDBSCAN(metric='precomputed')
clusters = model.fit_predict(matrix)
min_cluster_size and min_samplesmin_cluster_size=12&min_samples=2gives less noises thanmin_cluster_size=12&min_samples=3: It's because we need at leastmin_samplespoints to determine a core points. That's why the biggermin_samples, the harder to form a cluster, or the more chances we have more noises.min_cluster_size=7&min_sampls=3gives less noises thanmin_cluster_size=12&min_samples=3: It's because we need at leastmin_cluster_sizepoints to determine a cluster. That's why the biggermin_cluster_size, the harder the form a cluster, or the more chances we have more noise.
Attributes:
- Label
-1means that this sample is not assigned to any cluster, or noise! clt.labels_: labels of clusters (including-1)clt.probabilities_: scores (between 0 and 1).0means sample is not in cluster at all (noise),1means the heart of cluster.
HDBSCAN and scikit-learn
Note that, HDBSCAN is built based on scikit-learn but it doesn't have an .predict() method as other clustering methods does on scikit-learn. Below code gives you a new version of HDBSCAN (WrapperHDBSCAN) which has an additional .predict() method.
from hdbscan import HDBSCAN
class WrapperHDBSCAN(HDBSCAN):
def predict(self, X):
self.fit(X)
return self.labels_Reference
- Official doc -- How HDBSCAN works?
💬 Comments